Time to get to grips with your data
With Python, pandas and seaborn in your toolbox, you too can develop data exploration superpowers.

In biological research, we're currently in a golden age of data. It's never been easier to assemble large datasets to probe biological questions.
But these large datasets come with their own problems:
- How to clean and validate data?
- How to combine datasets from multiple sources?
- And how to look for patterns in large, complex datasets and display your findings?
These are the questions that come up again and again, from multiple researchers, in every course I run.
The solution to these problems comes in the form of Python's scientific software stack. The combination of a friendly, expressive language and high quality packages makes a fantastic set of tools for data exploration.
But the packages themselves can be hard to get to grips with. It's difficult to know where to get started, or which sets of tools will be most useful.
You may have already encountered this. If you look at the matplotlib website, it's clear that it's a powerful charting tool - but looking at the tutorial can be daunting. The same goes for pandas: it can carry out almost any type of data manipulation, but that same power makes it hard to get to grips with.
Happily, learning to use Python effectively for data exploration is a superpower that you can learn. With a basic knowledge of Python, pandas (for data manipulation) and seaborn (for data visualization) you'll be able to understand complex datasets quickly and mine them for biological insight.
You'll be able to make beautiful, informative charts for posters, papers and presentations, and rapidly update them to reflect new data or test new hypotheses.
And you'll be able to quickly make sense of datasets from other projects and publications - millions of rows of data will no longer be a scary prospect!
In this book, I have drawn on years of teaching experience to give you the tools you need to answer your research questions. Starting with the basics, you'll learn how to use Python, pandas, seaborn and matplotlib effectively using biological examples throughout.
Just the best bits of the best data exploration packages
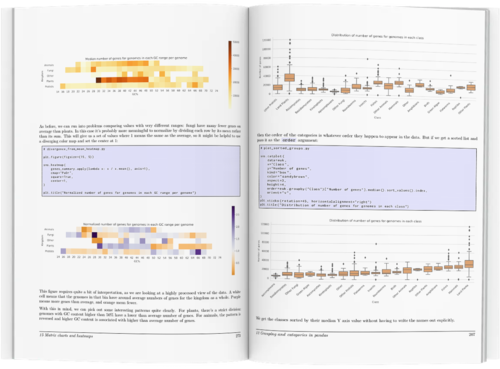
Rather than overwhelm you with information, the book concentrates on the tools most useful for biological data. Full color illustrations show hundreds of examples covering dozens of different chart types, with complete code samples that you can tweak and use for your own work.
The book is designed to help you get over the most common obstacles that we encounter with biological data.
You'll learn what to do if:
- your input files have errors, or missing data.
- your input files are too big to fit in memory
- you need to combine data from multiple sources
- you have to visualize datasets with thousands of rows or millions of columns
- you need to make complex filters for your data
- your data are in the wrong format for the analysis you want to do
Once you understand the basics of pandas, seaborn and matplotlib, the chapters on visualization will show you how to make sophisticated charts with minimal code and how to best to use color to make clear charts.
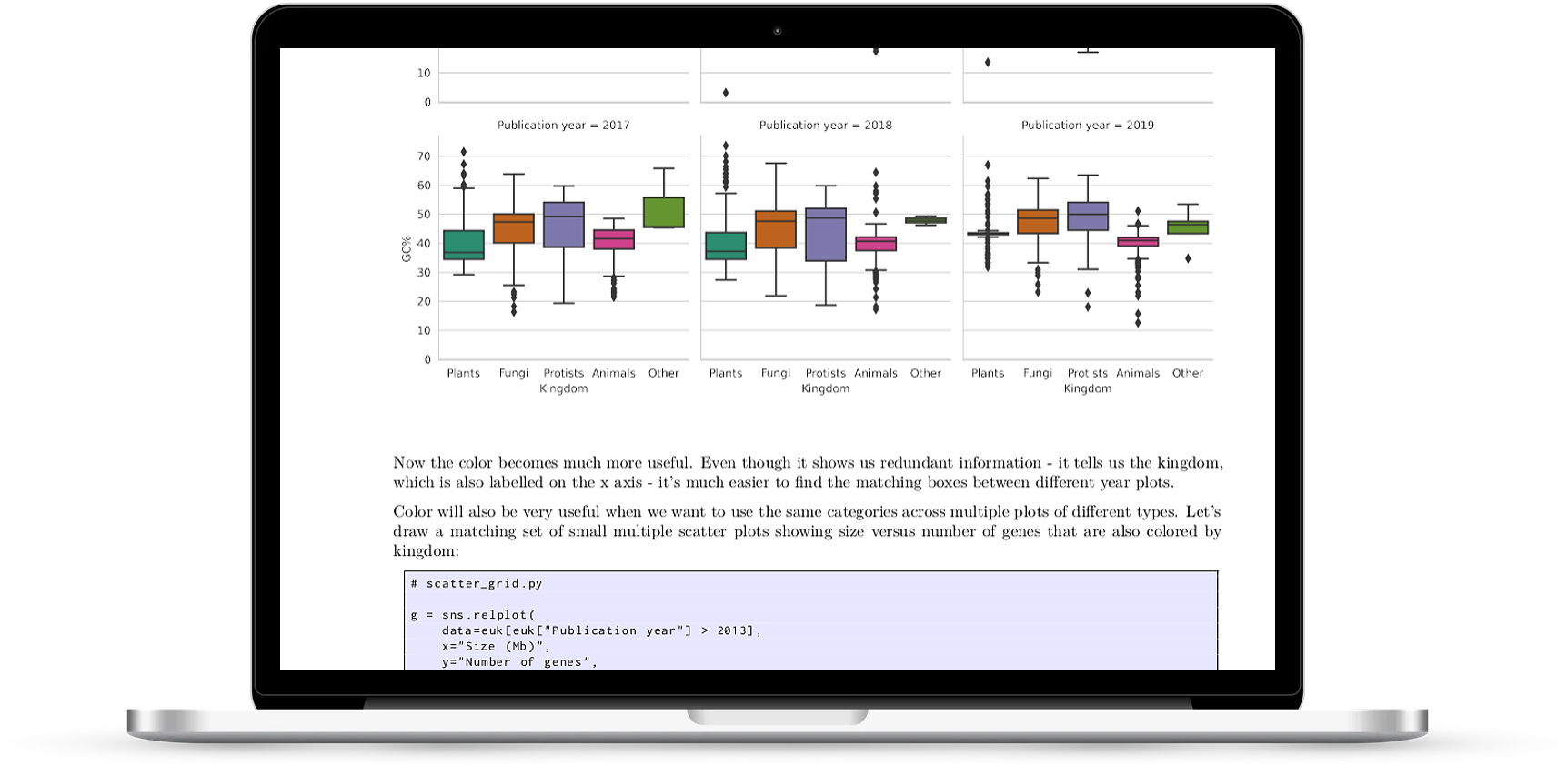
All the chart types you’ll need
The book covers the most basic charts that we use every day - histograms, scatter plots and boxplots - and more exotic charts like clustermaps and violin plots - all with full working code and biological examples.
For getting started with data exploration in Python, the step-by-step approach offered by the book beats everything else. But the real power of Python's data processing stack becomes apparent when you combine the individual tools in a single project.
That's where the videos come in.
In each of the four detailed videos, we'll take a single biological dataset and walk through all the steps involved in analyzing it, starting with publicly available data files and ending with our final figures. The videos give us a chance to explore different types of data, demonstrate tips and techniques that don't fit in the book, and use visualization to answer interesting biological questions.
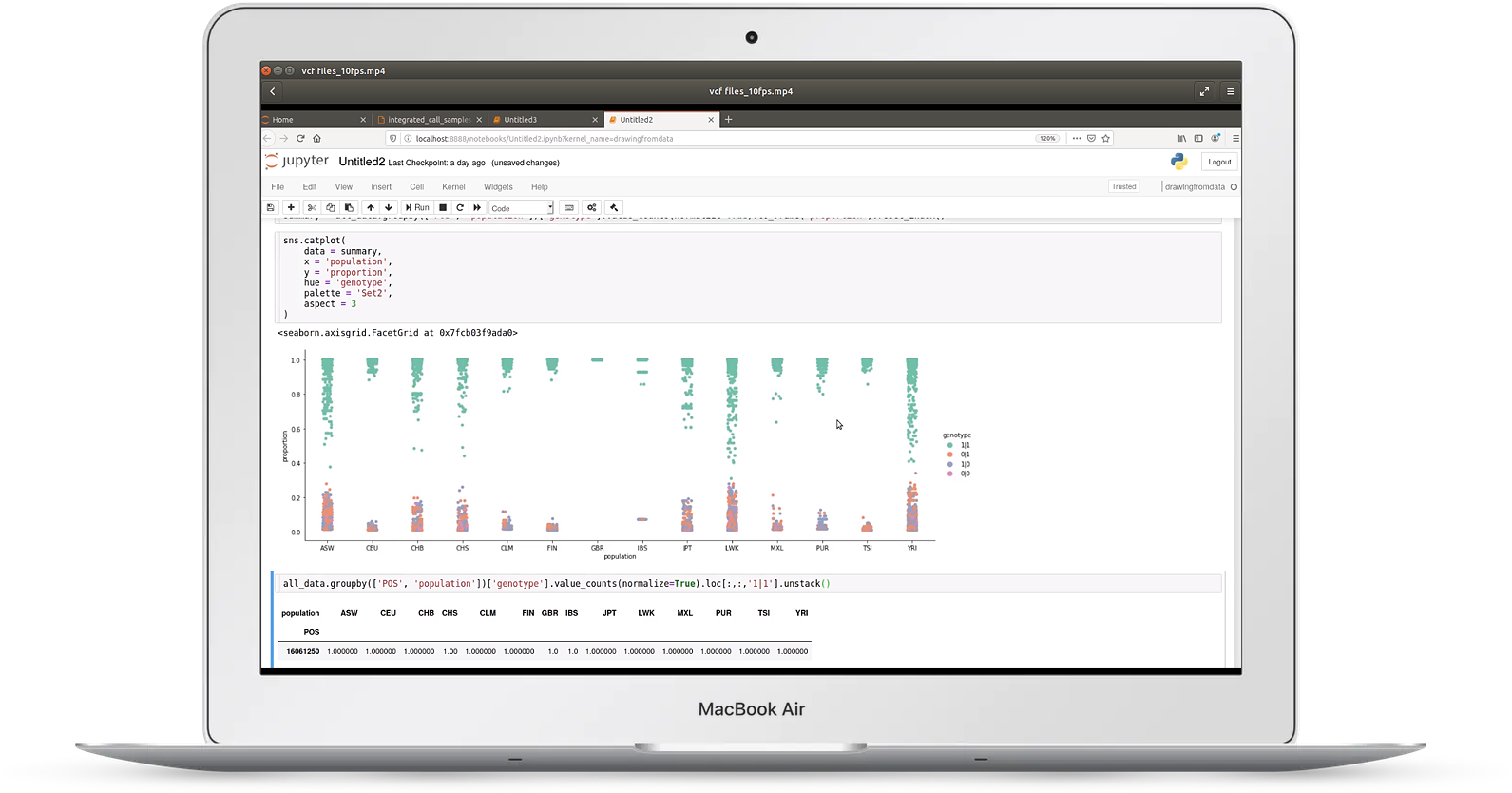
Video 1: VCF files
Video one discusses reading a large variant call format (VCF) file taken from the 1000 genomes project
In it you'll learn:
- how to benchmark and optimize time/memory usage for large files
- how to chunk input to deal with files too big to fit in memory
- how to filter genotypes
- how to merge sample and genotype data
- approaches to plotting genotype frequencies
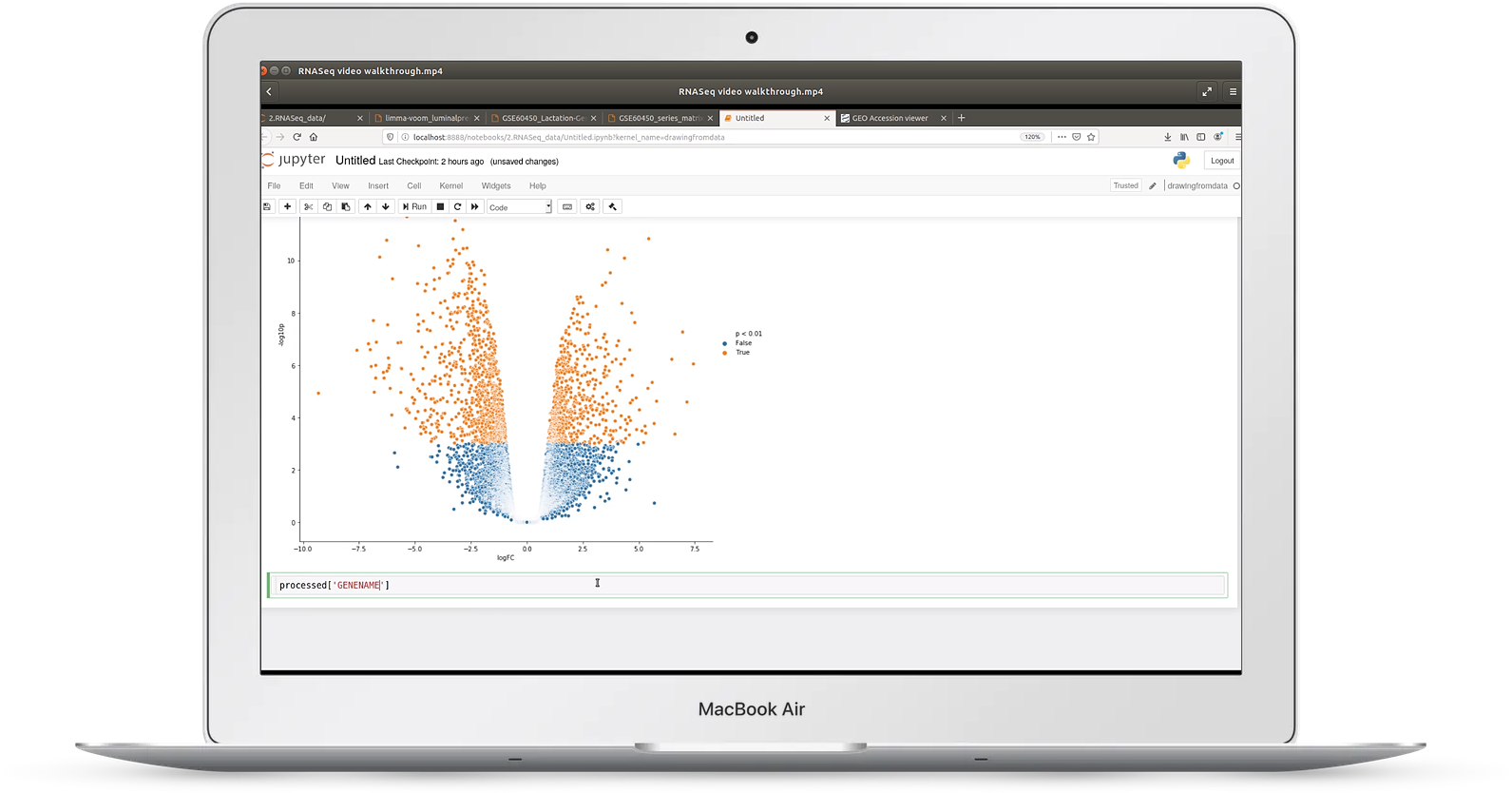
Video 2: RNASeq expression data
In video two, we look at an example of RNASeq gene expression data taken from the Gene Expression Omnibus (GEO)
In it we cover:
- how to transpose awkward data files
- how to use visualization for quality control on read count data
- how to cluster sample replicates
- making volcano plots and MD plots
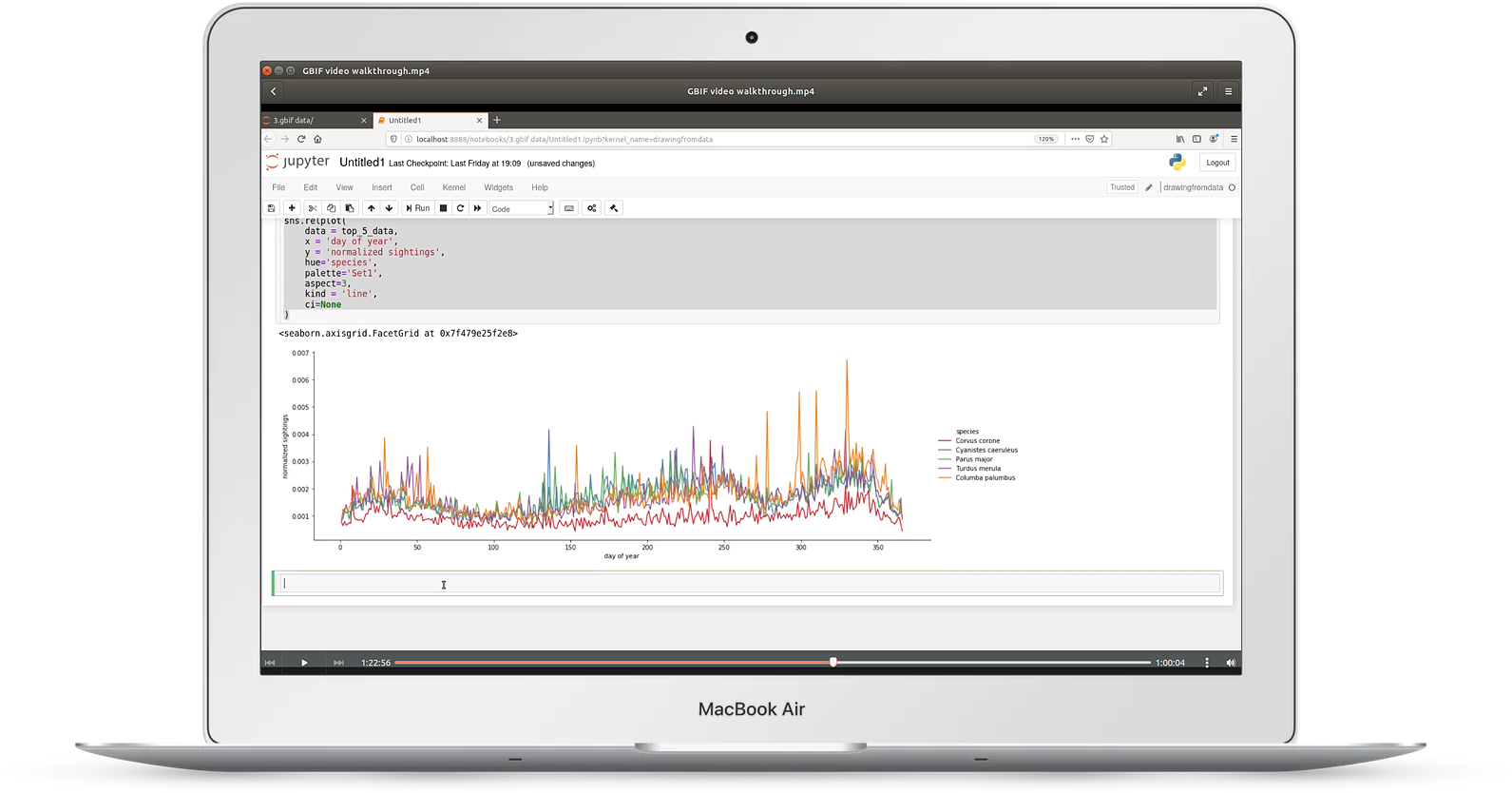
Video 3: biodiversity data
In video three, we take a look at geographical biodiversity data taken from GBIF
This video covers:
- choosing relevant columns from huge datasets
- log/log plots
- analyzing time series data, including resampling
- making geographical distribution plots
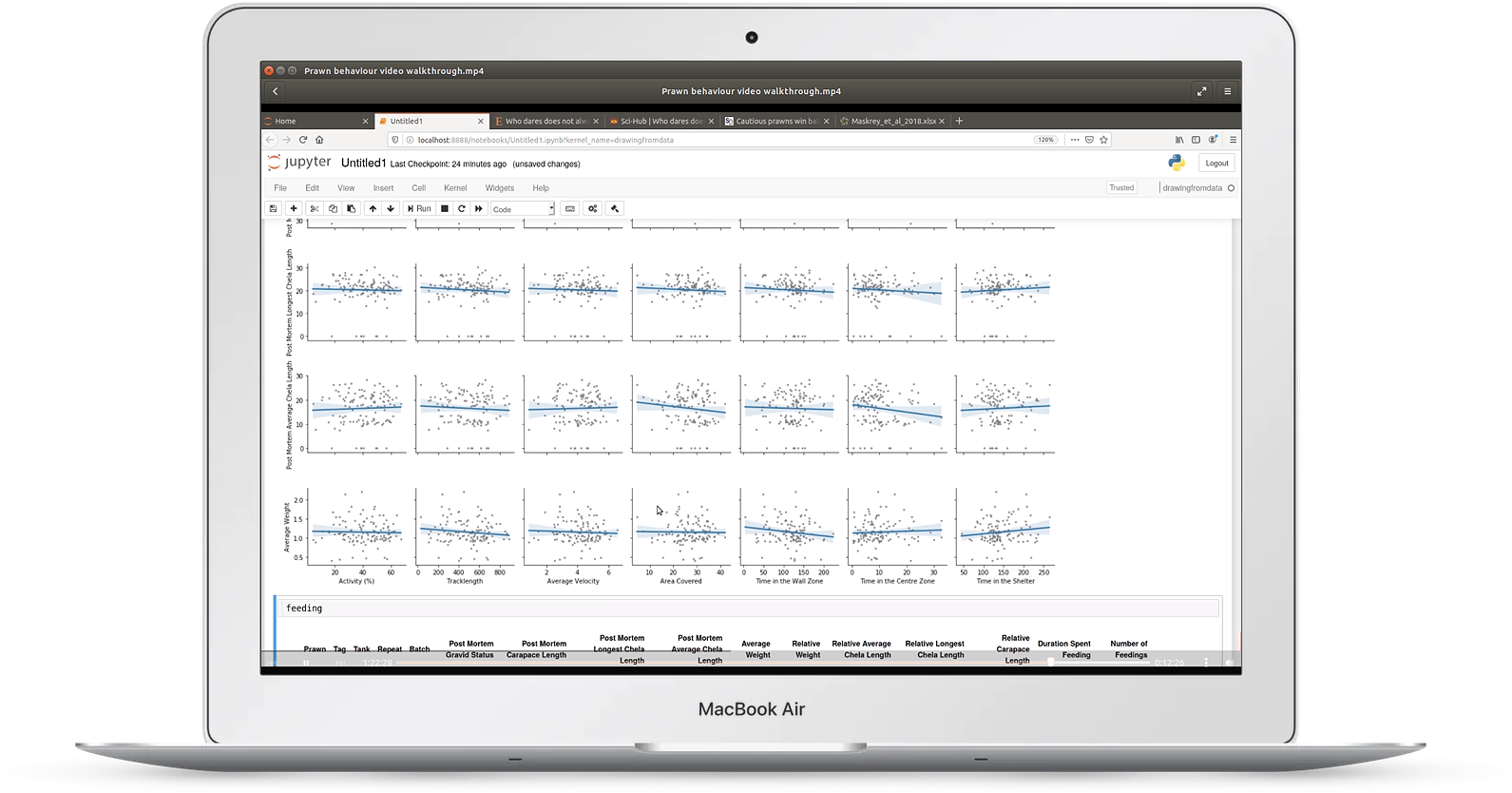
Video 4: experimental behavior data
In video four, we look at an example of an animal behavior experiment
You'll learn:
- how to read Excel files with multiple sheets
- how to read data files directly from the web
- using visualization for quality control of repeated trials
- finding correlations and confounding variables using regression plots
Just like in the book, all the video files come with working code in Jupyter notebooks that you can use to run the same analysis live, or tweak for your own research.
If you work with data of any size, getting to grips with data exploration in Python is one of the biggest boosts you can make to your research and your career.
Free your data from Excel! Transform your messy spreadsheets into clean, tidy tables! Understand your data better!
Ready to get started? Check out the packages below (and if you want to see a complete chapter list, scroll down to the bottom of the page).
All of the packages come with a no-questions-asked refund policy so you can buy with confidence. My goal with these books and videos is to make them directly useful to you - if they don’t work for you, you can get your money back right away.
You can pay securely with a credit card or with Paypal. If you need an invoice instead, just email martin@pythonforbiologists.com and we’ll arrange it.
The complete package: bookshelf plus videos

Everything for complete beginners: the Biological Data Exploration book, the two previous Python for Biologists books, and all the videos
This is the complete package, intended for those who’ve never used Python before, or who want a refresher before diving in to the data exploration material.
It includes the first two Python for Biologists books (Python for Biologists and Advanced Python for biologists), which together will take you from the very basics of programming and Python to give you all the background you’ll need to follow everything in the data exploration book.
These two books, along with the Biological Data Exploration book, come as searchable, DRM-free PDF files that you can keep forever and read on any device, along with exercise and example files to practice on.
You’ll also get the dataset walkthrough videos as high definition files that you can download and watch on any device. The videos come with interactive Jupyter notebook files that you can run, edit, and reuse for your own datasets.
Your files will be delivered by email, so you can start reading (and watching) right away. And you’ll get free access to any updates to the books (for example, when code changes to reflect changes in the libraries) and videos (for example, when new videos are added).
🛒 Click here to buy the complete package now for $169
The bookshelf package

The Biological Data Exploration book plus the previous two Python for Biologists books
Don’t like videos? This package includes the first two Python for Biologists books (Python for Biologists and Advanced Python for biologists), along with the Biological Data Exploration book.
The books come as searchable, DRM-free PDF files that you can keep forever and read on any device, along with exercise and example files to practice on.
And you’ll get free access to any updates to the books (for example, when code changes to reflect changes in the libraries).
🛒 Click here to buy the bookshelf package now for $79
Just the book
The Biological Data Exploration book, with example and data files
Don’t like videos and already know the basics of Python? This package includes the Biological Data Exploration book.
The book comes as a searchable, DRM-free PDF file that you can keep forever and read on any device, along with example code and data files to practice on.
And you’ll get free access to any updates to the book (for example, when code changes to reflect changes in the libraries).
🛒 Click here to buy the book now for $39
Frequently asked questions:
What’s covered in the book?
Rather than trying to give an exhaustive tour pandas, seaborn, matplotlib and numpy (each of which could fill several books), the book concentrates on the most useful parts of each library. Here’s a complete list of chapters and topics:
- getting data into pandas: series and dataframes, read_csv, dtypes/info/describe/head/len, missing data, giving column names
- working with series: getting a single column, descriptive statistics, value_counts, broadcasting operations, numpy vectorized ufuncs, string methods, selecting multiple columns, setting an index, dropna,
- filtering and selecting: boolean masks, basic filtering, isin, selecting with strings, multiple conditions, filter/select/aggregate pattern
- pandas examples: turning series into list, iterating over unique values
- intro to seaborn and plotting distributions: imports, distplot, setting title, distplot in a loop, relplot, hue and size for numerical values, adding a new column and plotting
- special types of scatter plots: alpha/size/sample/hexbin/contour for large numbers, lmplot for regressions, pairwise plots
- conditioning charts on categories: hue with category, size for category, style for category, small multiples with row/column, multiples with relplot
- categorical axes wtih seaborn: about different types of categories, strip plots, swarm plots, multiples, box plots, problems with order, boxplots hide distribution details, violin plots, boxen plots, bar plots, point plots, line charts, count plots
- styling figures with seaborn: three levels (seaborn high. seaborn low, matplotlib), aspect/height, labels, styles and contexts, passing keywords,
- working with colours in seaborn: setting single colours, setting palettes, sequential data, don't use rainbows, custom sequential, categorical palettes, redundant information, diverging palettes, when to use colour, matching between charts, colour plus style, displaying redundant catfor book layoutegories, adding metadata, highlighting categories, using colours consistently, don't reuse
- working with groups in pandas: types of categories, uniqueness, groupby, grouping on multiple columns, aggregating, turning into dataframes, filtering, transforming, iterating over groups, sorting to get group names
- binning data: simple binary with filter and replace, increased options for visualisation, using pd.cut, range, uneven bins, exponential bins, using size for ordered categories, turning categories into ordered ones.
- Long vs wide form and indices: why long data is best for visualization, using unstack to make a summary, using melt to get data into tidy form, setting an index, index performance, multi indexing, index slicing and loc
- Matrix charts: displaying summary tables, setting scales, annotation, missing data, lots of categories, diverging palettes, binning, custom annotation, clustering walkthrough, row/col cluster, normalizing, color annotation, bubble grids, plotting context
- Tricky data files in pandas: awkward input files, skiprows, setting names, using columns, footers, comments, thousands/decimals, boolean values, method chaining, assign and pipe, concat, adding a column by assigning a series, merging, inner/outer, dealing with large datasets, skipping columns, categories, precision
- Using facet grids directly: making a facetgrid, using map for simple things, using map_dataframe with custom functions, reusing custom functions, using hue for single charts, small multiple heat maps
- Unexpected behaviours: missing groups in groupby, fixing it with categories, breaking it with multiple grouping, workarounds, unsorted categories after unstacking, min_count in sum, odd scales in seaborn
- High performance pandas: looping vs. vectorization, looping vs. apply, apply on dataframes, caching, replace and memoization, sampling large datasets, categories, indices, unique indices
- Further reading: datetimes, alternative syntax, plotting directly from pandas, jupyter widgets, bokeh, machine learning, statistics
Do I need to know Python in order to follow the book?
Yes - you don’t need to be a Python expert, but you do need to know the basics: the book isn’t intended for complete beginners. If you’ve never used Python before, you’ll need to learn the core of the language first. You can do this by buying one of the bookshelf packages (which includes Python for Biologists, which is intended for complete beginners), or following various introductory Python tutorials online (including the one on this site).
Who are you?
Hi, I’m Martin - formerly a bioinformatics researcher and lecturer at the University of Edinburgh; now a freelance Python writer and trainer. See the about page for more info.
Can I buy a group license for my lab/students/colleagues?
Sure, drop me an email martin@pythonforbiologists.com and we’ll work something out.
